docker run -p 4317:4317 -p 4318:4318 \-v </path/on/host/where/to/save/files>:/parquet:z \Replace with an actual path on the hostmishmashio/opentelemetry-parquet-server
Getting started with OpenTelemetry
Here you can find open source code that we developed because we found it useful in our own work. We share it with the open source community because we believe it might be useful for your own software development effort too.
The projects here are not directly related to our distributed database. See our integrations section for open source that you can use along with mishmash io.
Collect telemetry data
Easiest way to get started with OpenTelemetry is to use an existing app, like an app you’re currently working on, and save some telemetry data from a run of that app.
To do this you will need:
- an agent or auto-instrumentation plugin for your programming language
- our simple Stand-alone Apache Parquet server
Additional information:Zero changes to your code
OpenTelemetry supports auto-instrumentation - agents (or other tools) that can attach themselves to a running program and automatically collect telemetry as code is executed. It can aslo ‘understand’ when your app uses popular frameworks like logging or REST client and server methods without you having to change anything in your app code.
Jump to how to auto-instrument , and . For other languages go to
In this simplest scenario - when you launch the instrumented app on your computer, the OpenTelemetry agent (or plugin)
will connect to our Parquet server over a network protocol called OTLP and will export logs, metrics and/or traces
to it. The server receives these signals and saves them in Apache Parquet files for later use:
In just two steps you can collect your first telemetry:
- Launch our Stand-alone Parquet server
- Instrument and launch your app
See how to do this in the next paragraphs.
Launch our Stand-alone Parquet server
Additional information:Why Parquet?
To get ready to collect your telemetry data launch the server on your computer:
Note: replace </path/on/host/where/to/save/files> with the directory where you’d like the parquet files to be saved.
In a few seconds the server will be ready and expecting OpenTelemetry agents to connect and export data to it.
Leave it running for now, as you’ll have to do one more step to get your first telemetry data saved.
Instrument your app
Additional information:Many ways to instrument your code
Auto-instrumentation typically plugs into your run-time environment (interpreter, virtual machine and so on) and automatically collects telemetry from your running code, without you having to change a single line.
Let’s set it up first:
-
Using the links to the official OpenTelemetry website above - download and install the auto-instrumentation agent for your programming language.
-
Open a new shell and set some configuration variables:
That’s it! Now, lets instrument and launch your app. This also differs depending on what programming language you used to develop it.
For Java, do something like this in the same shell as above:
Note: replace </path-to-agent-jar/> with the actual directory where you downloaded the java agent jar.
For Python, again, in the same shell as above:
And for node.js (also in the same shell as above):
Additional information:For brevity
An existing app might have a more complicated way of launching - like requiring additional parameters or steps to execute. We assume you will be aware of the proper way of launching it.
Also, for brevity, we’re not listing examples for all languages supported by OpenTelemetry. If you’re using another programming language - see the offical OpenTelemetry docs.
When your app launches, its agent will connect to the telemetry server and start exporting signals. Go and make your app do something - browse its GUI, make some REST requests to it, etc.
Watch the folder where the parquet files are (configured earlier, when you launched the parquet server).
In it, you’ll see files named like logs-1711610327006-0.parquet, metrics-1711610327006-0.parquet and traces-1711610327006-0.parquet.
Wait until the files grow to a comfortable size and stop your app and the parquet server. Your first telemetry signals are now collected and you can proceed to the next step - exploring the data!
Visualize telemetry
Now that you have saved your first telemetry, let’s explore it to get a feeling of what it contains.
A word about schemas
First, let’s sketch roughly how OpenTelemetry organizes the data it emits. So far we’ve mentioned it contains log messages, metric values and code traces, but there’s also meta-data to help identify who produced a given signal.
With experience, that meta-data will become increasingly valuable to you, as it allows you to understand the context within which a given signal was emitted and how to relate it to other signals in the same context.
There are two additional OpenTelemetry concepts that we haven’t intruduced yet and they’re the major containers of meta-data:
- Resource - representing a single emitter of telemetry - one process running on a given host or within a given container
- Scope - a logical component within a resource - a single module, library or framework
For example, if your app is running one REST backend service and a database - there will be two distinct resources - one for the backend and one for the database. If, at some point, your app scales its backend to two running instances - you’ll have two ‘backend’ resources and one ‘database’ resource.
Similarly, your backend service is likely to be using a REST-server library and a database client library. These will be typically two distinct scopes within each ‘backend’ resource.
Even though logs, metrics and traces are emitted separately, resources and scopes are common to all of them.
Logs are emitted like this:
…metrics like this:
…and finally traces:
There’s one major point to be made here: our Parquet server ‘flattens’ incoming data before writing it to the files.
To make files simpler to use:
- a row in a logs file contains a single log message
- a row in a metrics file contains a single data point of a metric
- a row in a traces file contains a single span record
- all rows in all files contain the resource and scope
Armed with this knowledge we can now move to exploring the data.
Visualize with a Jupyter notebook
If you’re no stranger to Python, Pandas and Jupyter notebooks you can easily explore the files saved earlier.
Additional information:Data in these examples
In the following examples we’re using telemetry saved from the Parquet server itself. Your recordings might differ slightly, but the structure will be the same.
To begin, make sure you have Jupyter and Pandas installed. You’ll also need to read the parquet files into DataFrames.
Then start Jupyter:
…create a new notebook and in it add and execute these paragraphs:
-
Import pandas:
-
Set some DataFrame visualization options:
-
Create logs, metrics and traces DataFrames:
Note: replace the filenames above with the correct path on your computer.
Logs and meta-data
Now, just type logs_df in an empty notebook paragraph to explore some logs. At the start, you will see
some columns like resource_attributes, scope_name, etc - more on these later. For now, just scroll to the
right to see some log messages:

Here you can see the log message text, severity, etc.
Now, let’s get back to the resource meta-data. It is basically contained in these columns:
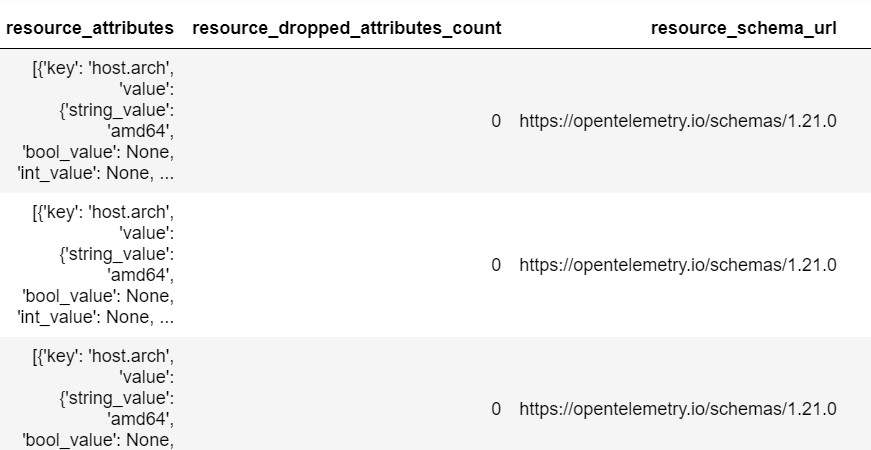
but the most important one is the resource_attributes. These attributes describe an individual telemetry emitter. In
this example it is the Parquet server process itself. Let’s expand the list of attributes and their keys and values. Just
execute something like this in a new notebook paragraph:
…and you’ll get a result similar to this:
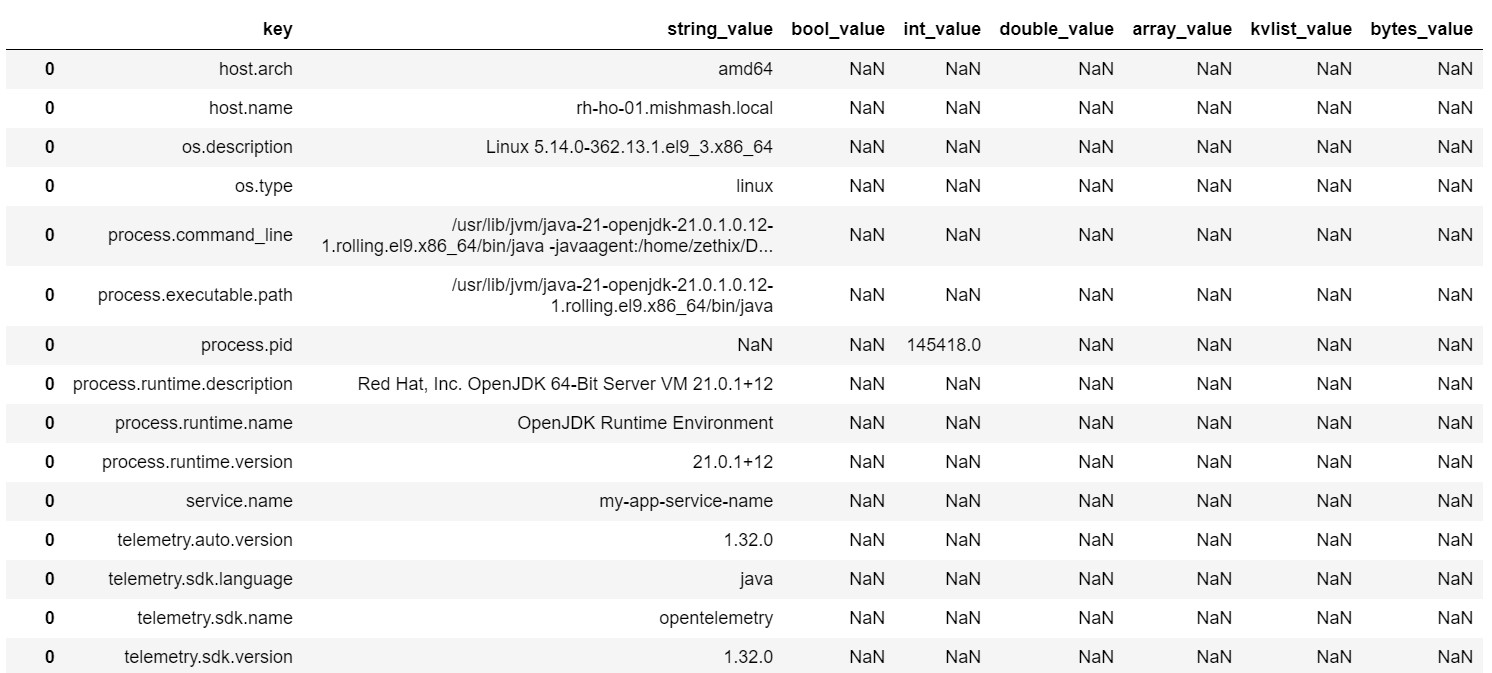
As you can see, in this case the resource_attributes describe an individual process (PID 145418),
running OpenJDK version 21.0.1+12 on a linux host rh-ho-01.mishmash.local, and we have named this
particular service my-app-service-name.
Additional information:Resource-, scope- and other attributes
Except for the service.name attribute that we configured when instrumenting the server, all
others were automatically added by the agent.
You can add more attributes to better describe your resources - like setting the environment (‘production’ or ‘test’), but this is beyond the scope of this document.
Similarly, a scope is defined by columns like:

These are individual entries generated within the scope of our Parquet server. We specifically named this scope OpenTelemetry Server,
as logically it’s a separate part of the resource. Within this resource, there are more scopes and you can get a list of all of them
by running something like this:
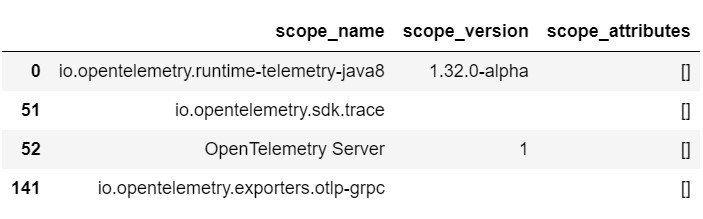
You can see here that OpenTelemetry Server is only one of the scopes with others being added automatically by the Java agent.
Metrics
Having seen logs above, let’s now explore some metrics. Metrics are a bit more complex than log messages, as OpenTelemetry does not report every individual change of a metric value. Doing this will generate too much load and traffic, so instead, OpenTelemetry ‘aggregates’ each metric and only reports the ‘aggregated’ value over a time period.
Additional information:Metric types and aggregation
Depending on what ‘aggregation’ was chosen, metrics will have different types - like GAUGE,
SUM or HISTOGRAM. They may also be reported as DELTA or CUMULATIVE metrics too.
You can learn more about the different types of metrics and how to configure them in the official OpenTelemetry documentation.
In here, we’ll just show you quickly some metrics. Here’s a GAUGE metric reporting the actual
CPU load on the host every once in a while:
Run the code above and you’ll get something similar to this:
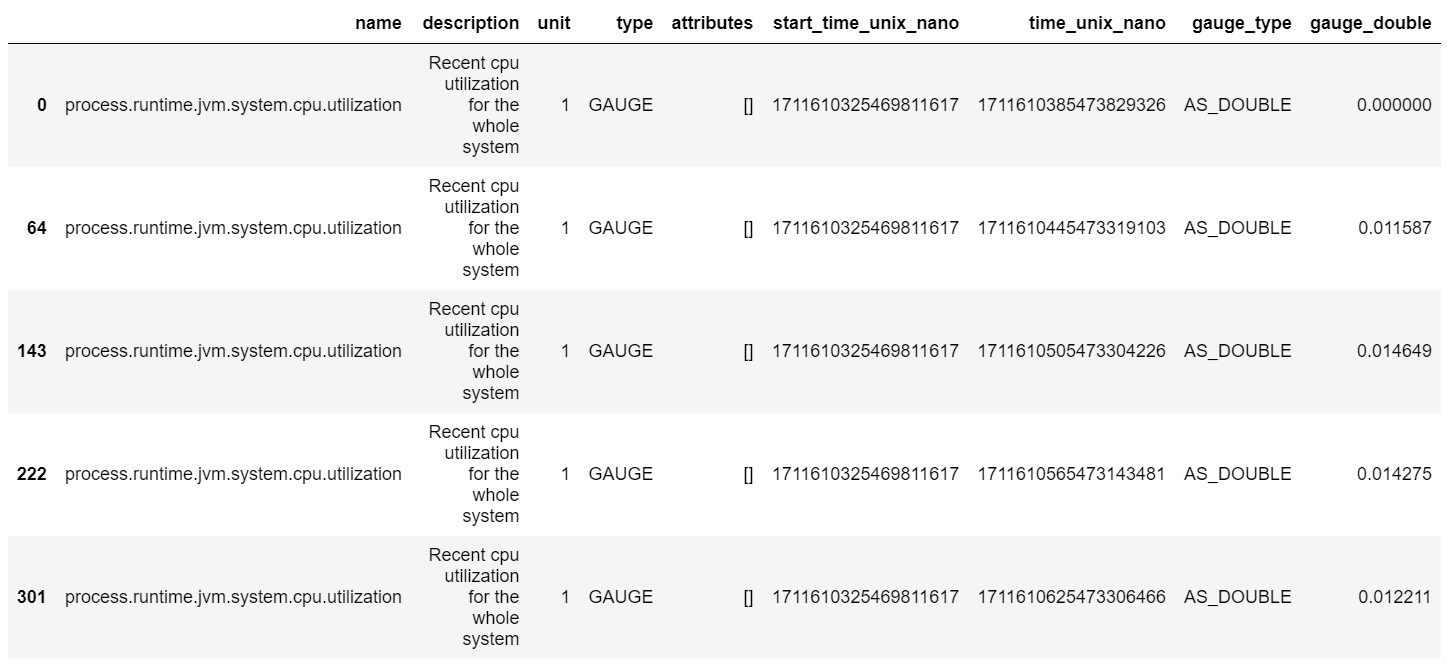
Changing the code above you can explore other types of metrics and how they are reported over time.
Traces
Logging messages and reporting metrics are very well known practices in software development. Tracing, on the other hand, is often overlooked.
Additional information:What are traces?
Traces ‘emit’ a path taken by a running code from a starting point to a logical completion. Either by completing successfully or until, say, an error is encountered.
These emitted paths are called spans.
When your code ‘enters a trace’ a span is opened and until closed, it will accumulate events, links and other meta-data describing what the path taken by the code during the lifetime of the span.
Spans can also be nested into other, larger spans to provide a break-down of an end-to-end process within the code. For example, handling an incoming REST request may open a span as a parent, and within it each logical part of the request handlers can add their own child spans. A database query module might open its own ‘inner’ span to capture how much of the REST-request handling was spent on waiting on the database.
Let’s explore some spans in our traces DataFrame:
Running the above produces:

Spans also have their meta-data, like here for example the Java agent is reporting which thread is running through a given span:
Exploding the attributes column shows something like this:
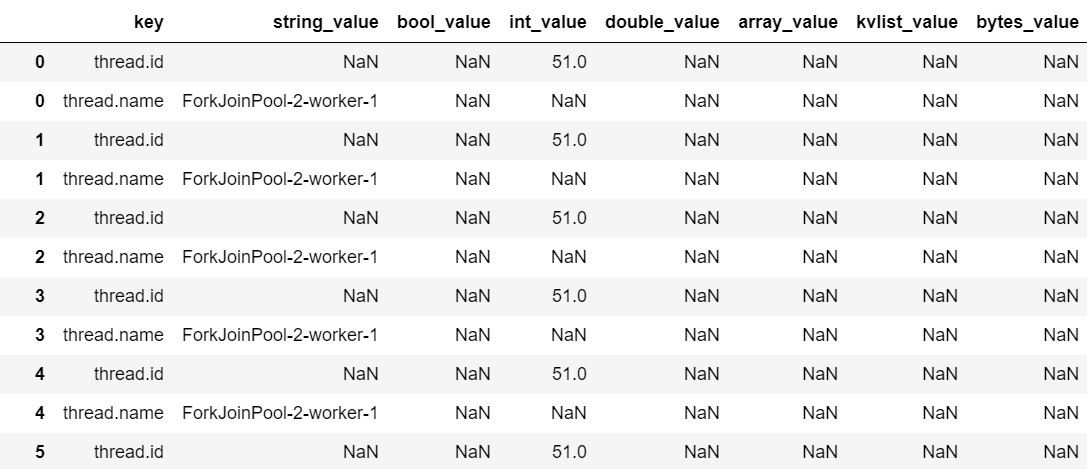
In our Parquet server we’ve added spans to improve its own observability, and inside them we report events - basically points in the path of, for example, processing incoming metrics.
To get the events within a span, run something like this in your notebook:
And it will display a list of events with their timestamps, names, attributes and so on:
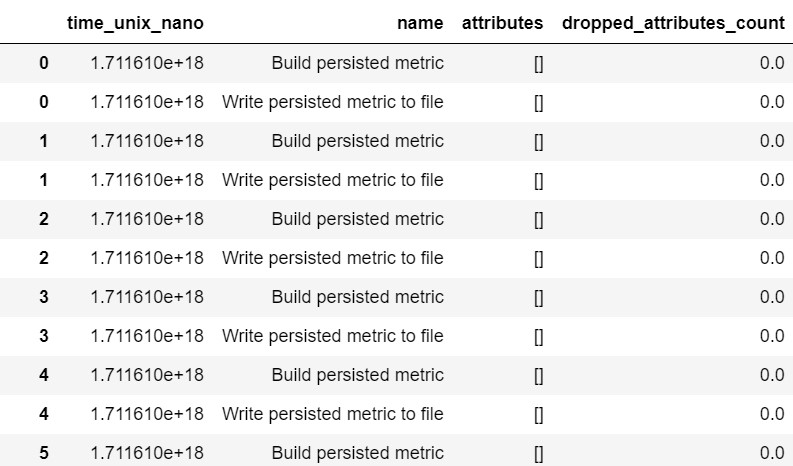
The examples in this section are using data we collected from the Parquet server itself, for the purpose of writing this document. Data you collected on your computer will be different, but hopefully, by reaching this point you’ll be comfortable to modify the example code here to suit your needs.
Visualize with Apache Superset
Additional information:Section under development
This part of our website is still under development and major parts of its content are not published yet.
Follow us on social media to get notified when new content is released.
While notebooks are good to do get a feeling on raw telemetry data often you need to quickly see a bunch of metrics (and how they might be affecting each other), explore the durations of spans and more. It’s easier if you create some charts and organize them logically into dashboards that you can access again and again.
For this reason, we’ve also built some open source telemetry visualization tools, including charting with Apache Superset.
As we release them this section will be updated with more details.
Next steps
Extend your code tests with telemetry to further ensure the quality of your systems.